Unsere Produkte und Leistungen
Referenz-Sensorenaufbau auf dem Dachträger




Unsere Sensorlösung bietet Unterstützung bei der Entwicklung von Algorithmen im Bereich ADAS und autonomes Fahren an. Die Basisversion, die wir direkt vermarkten, zielt auf Benutzerfreundlichkeit und einem guten Preis/Leistungs-Verhältnis ab. Um Daten aufzuzeichnen muss man lediglich den Dachträger mit den verbauten Sensoren und Komponenten auf das Fahrzeug montieren und einen Rechner o.ä. an den verfügbaren LAN-Ports verbinden. Alle Komponenten sind auf der Dachträger-Einheit fest verbaut, vorkalibriert und synchronisiert.
Mit unserem Design können wir auch individuelle Lösungen für unsere Kunden implementieren, die den spezifischen Anwendungsfällen und Anforderungen entsprechen. Das IEEE 1588-2008 Precision Time Protocol (PTP) kann verwendet werden, um unsere auf dem Dach montierten Sensoren mit der Seriensensonsorik des Zielfahrzeuges oder auch mit anderen externen Referenzsensoren zu synchronisieren.
Softwarepaket
Durch den Kauf einer unserer Standard- oder kundenspezifischen Sensorlösungen erhalten Sie Zugriff auf unser Softwarepaket, das viele nützliche Tools enthält.



Daten Viewer
Der Viewer ermöglicht eine einfache und intuitive Visualisierung der aufgezeichneten Daten. Sowohl Roh- als auch post-prozessierte Daten von Algorithmen oder manuellem Labeling können mithilfe dieses Tools veranschaulicht werden. Durch die Echtzeitvisualisierung können sogar Aufzeichnungen von mehreren hunderten Gigabytes problemlos auf gängigen Rechnern in den Ubuntu, Windows oder MacOS Betriebssystemen inspiziert werden. Dadurch dass der Viewer kostenfrei für jeden zum Download verfügbar ist, können aufgezeichnete und post-prozessierte Daten einfach mit weiteren Kunden oder Dienstleistern geteilt werden.



Automatisiertes Post-Processing
Simultaneous Localization and Mapping Das SLAM Modul verwendet die aufgezeichneten IMU und Lidar Daten und berechnet die Lokalisierung des Ego-Fahrzeuges in der gesamten Aufnahme. Optional kann auch ein GNSS Signal in der Berechnung des SLAM's mitbenutzt werden, was die Ergebnisse verbessert. Die Lokalisierung wird dann, zusammen mit weiteren Modulen zur Bereinigung dynamischer Artefakte, verwendet, um eine globale statische Karte zu erzeugen. Diese globale Karte wird über die gesamte Aufnahme berechnet.
Deep Learning Das Softwarepacket beinhaltet auch die Möglichkeit, automatisiert semantische Segmentierungen und semantische Instanz-Segmentierungen mithilfe von vortrainierten neuronalen Netzen zu generieren. Dazu werden der Pyramid Scene Parsing Network und der Mask R-CNN verwendet. Die Ergebnisse aus diesen Berechnungen werden von weiteren Modulen im Softwarepacket zusammen mit den Lidardaten fusioniert. Der Viewer kann die Outputs auch aus diesen Modulen zusammen mit den Rohdaten visualisieren.


Sensor Kalibrierung
Dieses Modul kann benutzt werden um die Sensoren auf unserem Dachträger neu zu kalibrieren. Darüber hinaus kann man damit auch Lidar, Kameras oder auch Inertialsensorik der Seriensensorik oder anderer Referenz-Sensorsysteme kalibrieren.
Daten Exporter
Alle aufgezeichneten und post-prozessierten Daten werden in Open-Source-ROS-Messages exportiert und in rosbags gespeichert. Es werden nur die Standard Message Types aus dem original ROS Quelltext verwendet. Auf dieser Art und Weise kann jeder die aufgezeichneten und post-prozessierten Daten verwenden, ohne Abhängigkeiten von unserer Software zu haben.
3D Labeling Tool und Labeling Leistungen

Wir haben Software zum anreichern aufgezeichneter Daten mit 3D Bounding Boxen geschrieben. Diese ist im selben Framework wie das oben beschriebene Softwarepacket implementiert. Allerdings wird das Labeling-Tool als ein separates Produkt bzw. eine separate Leistung an Kunden vermarktet. Mithilfe unseres Labeling-Tools ist es möglich aufgezeichnete Daten semi-manuell/semi-automatisiert mit einer deutlich höheren Durchsatzquote als Konkurrenzverfahren zu labeln. Dies wird in zwei Labeling-Durchgängen erzielt.
Im ersten Durchgang werden alle statischen Objekte gelabelt. Die statische Karte aus dem automatisierten Post-Processing verschafft hier einen großen Vorteil und ermöglicht die Annotierung von statischen Objekten in Rekordgeschwindigkeit.
Im zweiten Durchgang werden dann entsprechend alle dynamischen Objekte gelabelt. Da die Bewegungen von Fahrzeugen und Fußgängern gewisse physikalische und intuitive Regeln folgen, werden hierzu diese durch Bewegungsmodelle parametrisiert dargestellt. Durch eine handvoll Messungen bzw. Labels ist es damit möglich, die Position und Orientierung der Objekte zu jeglichen Zeitpunkten zu interpolieren. Somit muss nicht kontinuierlich manuell annotiert werden werden, was Zeit und Aufwand spart.
Softwareentwicklungsdienstleistungen
aCVC, a Computer Vision Company UG (haftungsbeschränkt) ist in erster Linie ein Softwareentwicklungsunternehmen. Als selbstbewusste Softwareentwickler sind wir sicher, dass wir hervorragende Softwareprodukte für eine Vielzahl von Anwendungsfällen und Anforderungen erstellen können, und bieten daher unsere Entwicklungsdienstleistungen für Kunden an. Obwohl unsere Hauptstrategie darin besteht, auf bestimmte Ausschreibungen anzubieten, kann sich jeder gerne über unsere Dienstleistungen erkundigen. Wenn Sie nach Softwareentwicklungspartnern suchen, können Sie sich gerne bei uns melden und wir können besprechen, was wir für Sie tun können.
Portfolio Relevanter Referenzen in Computer Vision



Deep Learning
2D Objekterkennung YOLOnet ist eines der beliebtesten Open Source-Projekte in diesem Bereich. Wir haben Erfahrungen mit allen YOLOnet Versionen ab Version 3, einschließlich der "tiny" Versionen.
3D Objekterkennung Wir haben Erfahrung mit der Verwendung und dem Trainieren von Voxelnet und PointPillars für diverse Klassen und Lidar-Scanner. Dies sind zwei der am häufigsten verwendeten Open Source-Projekte für 3D-Objekterkennung in Lidar-Daten. PointPillars ist das aktuellere von den beiden und erzielt unserer Erfahrung nach eine sehr ähnliche Erkennungsrate wie Voxelnet, bei wesentlich schnelleren Laufzeiten.
Semantische Segmentierung Wir haben Erfahrung mit der Verwendung und dem Trainieren von PSPNet und SegNet in verschiedenen Use-Cases, sowohl mit Kamera- als auch Lidardaten. Im Lidar-Fall wurde die Punktwolke als ein Bild repräsentiert, das das Prozessieren der Lidar-Daten mit dieser Art von CNNs kompatibel machte.
Objektinstanzsegmentierung Wir haben Erfahrung mit der Verwendung und dem Trainieren des Mask R-CNN. Der Mask R-CNN kann sowohl für Objekterkennungs als auch für Objektinstanzsegmentierungs Use-Cases verwendet werden. Objektinstanzsegmentierungen sind jedoch besonders nützlich, wenn es sich um Sensor-Fusion-Setups handelt, die auch Lidare enthalten.
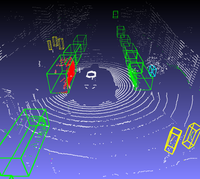

Sensor Fusion
Die Fusionierung verschiedener Sensoren und Algorithmen kann viele Vorteile haben, da sich ihre Stärken und Schwächen unterscheiden und sie sich somit gegenseitig ergänzen können. Ein Projekt kann durch eine sinnvolle Kombination klassischer Algorithmen mit Deep Learning Verfahren maßgeblich profitieren.



Simultaneous Localization and Mapping
Lidar SLAM Wir verwenden Google Cartographer als SLAM Backend für unser eigenes Sensor-Setup mit dem Livox Horizon-Scanner und haben die globalen Parameter entsprechend angepasst, um eine möglichst robuste und genaue Lokalisierung zu erhalten. Wir haben auch eine Konfiguration implementiert, die in Echtzeit ausgeführt werden kann und anderen ROS-Nodes Live-Lokalisierungsdaten senden kann. Wir haben auch Google Cartographer-Konfigurationen implementiert, die mit verschiedenen Sensor-Setups mit mehreren Lidars laufen. Darüber hinaus haben wir auch Erfahrung in der Verwendung des Open Source-Projektes Berkeley Localization and Mapping.
Visual SLAM Im visual SLAM Bereich haben wir die Open-Source-Projekte Direct Sparse Odometry und ORB-SLAM in mehreren Projekten verwendet und als Module abstrahiert. In diesen Use-Cases handelte es sich um Projekte ohne Lidar Sensor, die die Verwendung von visuellem SLAM erfordert haben.

Sensorsimulation
Carla, der MIT lizenzierte Open-Source-Simulator, ist ein nützliches Tool für Projekte in den Bereichen ADAS und autonomes Fahren. Unsere Hauptanwendung des Tools bestand darin, ein Auto mit dem integrierten Autopiloten durch die verschiedenen Karten, die das Tool anbietet, fahren zu lassen und währenddessen simulierte Rohsensordaten zu extrahieren. Wir haben diese Daten verwendet, um Deep-Learning-Modelle zu trainieren, die zur Objekterkennung mit realen Sensordaten verwendet werden sollten. Durch die Benutzung von Carla hat man die Möglichkeit große Datensätze automatisch generierter Trainingsdaten ohne Mehraufwand zu generieren. Ein weiterer Anwendungsfall war die Implementierung einer aktiven Kollisionsvermeidungsfunktion, die den Fahrer des virtuellen Autos daran hinderte versehentlich oder absichtlich mit anderen Objekten zu kollidieren. Durch diese Projekte haben wir Wissen und Erfahrungen darüber gesammelt, wie dieses Tool in diversen Szenarien eingesetzt werden kann, die von einer solchen Integration profitieren können.

3D Rekonstruktion
Von der Rekonstruktion mit einer einzigen Monokular-Kamera bis zur Verwendung mehrerer Kameras in Stereo- und Nicht-Stereo-Konfigurationen haben wir diverse Erfahrungen anhand einer Mehrzahl von Anwendungsfällen gesammelt. Wir haben mehrere Algorithmen in diesem Bereich implementiert, sowie Algorithmen und Algorithmenverbesserungen entworfen. Unsere Erfahrung umfasst die Verwendung und Integration einer Vielzahl von Bibliotheken und Open Source-Projekten in diesem Bereich.

Eye Tracking
Aufgrund der ungleichmäßigen Sehschärfe (die Fähigkeit feine Details zu unterscheiden) bewegen wir unsere Augen in einer bestimmten Art und Weise um unsere Fovea (der Bereich mit der höchsten Sehschärfe) auf die Bereiche zu richten, in denen wir visuelle Informationen erhalten möchten. Die Bewegung der Augen kann in verschiedene Arten von Augenbewegungen unterteilt werden, die zusammen mit den visuellen Inhalt den wir zu sehen wünschen, weiter analysiert werden können. Dadurch erhält man wertvolle Informationen über die interessanten Bereiche einer Szene, den Zustand des beobachteten Menschen und seiner Augen und auch vieles mehr. Um die Zusammenhänge dieser Faktoren realitätsnaher erforschen zu können, können Experimente durch den Einsatz tragbarer Eye-Tracking-Geräte auch außerhalb des Labors ausgeführt werden.
